
大数据、人工智能( Artificial Intelligence )像当年的石油、电力一样, 正以前所未有的广度和深度影响所有的行业, 现在及未来公司的核心壁垒是数据, 核心竞争力来自基于大数据的人工智能的竞争。所以不论是计算机专业的程序员,还是非计算机专业准备转行计算机的跨行人员都想学习大数据,从事大数据开发工作。
但是当你站在一个行业门外的时候,你更多的是看到他的价值和前景,这会促使你义无反顾地往里冲。但当你想要跨越这道门槛入门的时候,你开始考虑技术层面的困难,什么困难呢?那就是我对这个行业知之甚少,这个行业是否与我的想象相符?是否和我的发展方向一致?我应该从哪里开始?应该如何快速入门?
大数据这个行业也是一样,好像这个互联网时代,不知道大数据就落伍了一样,但很多一部分人也只限于了解了大数据这个词,并加上自己想象的定义。
那么大数据到底是什么?用来做什么?如何开始大数据的学习呢?今天我们从技术的角度来深入浅出聊一聊。
首先,大数据到底是什么?大数据只是一个统称。广义上,像大数据开发、大数据分析、大数据挖掘等对大数据的操作都可以统称为大数据。狭义上:大数据是指在一定时间范围内无法用常规的软件分析工具进行处理的数据集。所以从定义可以看出来,大数据最原始的本质其实就是数据集,只是数据集的规模、体量很大,大到我们无法接受使用常规软件处理所花费的时间。
大数据用来做什么?我们已经明确了大数据就是数据集,那么数据集用来做什么,当然是通过对数据集进行处理、分析,提取有用的信息用于各种业务之中。所以大数据的作用也是如此,通过提取大数据中有价值的信息,再利用这些信息进行业务赋能,促进智慧城市建设、企业用户画像、人工智能仿生、医疗疾病诊断等政、企、研、医行业的发展,为行业领域带来新的价值空间。
既然大数据有如此多的应用场景、广阔想象空间的发展前景,那么如何开始接触学习大数据呢?
为了大家能够真正明白,也为了能够达到深入浅出的效果,我们在下面说明大数据的各种处理手段时会经常拿常规数据和大数据来对比解释。
首先大数据的数据属性就决定了他的操作空间(处理流程),无外乎数据采集→数据存储→数据计算→数据应用。这些操作的背后几乎涵盖了当前大数据行业的所有产业链。
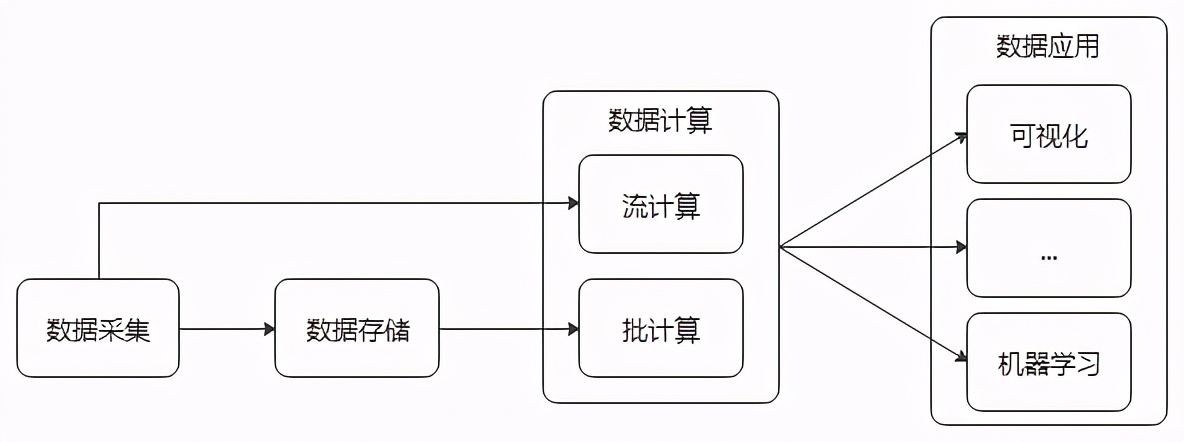
![]()
大数据处理流程
大数据采集是大数据整个体系的起始端。我们首先需要获取数据,传统数据的获取方式,比如学生信息的获取,我们可以采用Excel手写输入的方式获取。但是在这个互联网时代,动辄百万条、千万条数据,又有各种各样的数据源,比
如数据库、日志、物联网传感器等等,我们不可能再通过人工或常规Excel的方式去实时获取、汇总数据,这时候就需要针对这种超过普通数据集定义的超大数据集采用专门的采集工具,来提高数据采集效率,使每秒产生的成千上万数据能够及时被采集到指定的存储介质上,不产生数据积压,避免造成数据丢失。使用专门采集工具高效采集数据的过程就被叫做大数据采集。大数据采集,根据采集的数据源不同(数据库、日志、物联网信号…),采集的数据类型不同(结构化数据、半结构化数据、非结构化数据),会用到诸多适应于各自场景的采集工具,比如:Flume、Sqoop、Nifi…
Flume是Cloudera提供的(后来成为Apache开源项目)一个高可用,高可靠的,分布式的海量日志采集、聚合和传输的工具。主要用于采集日志类数据,由于Flume可以通过配置采集端采集模式(spooldir、exec)从而可以做到文件目录内新增文件的增量采集、文件内新增文件内容的增量采集。Flume还可以通过配置自定义拦截器,过滤不需要的字段,并对指定字段加密处理,将源数据进行预处理,实现数据脱敏。
Sqoop是在Hadoop(后面会介绍)生态体系和RDBMS体系之间传送数据的一种工具。最常用的还是通过Sqoop将RDBMS体系(Mysql、Oracle、DB2等)中的结构化数据采集并存储到Hadoop体系(HDFS、Hive、Hbase等)的数据仓库中。
Nifi,由于Nifi可以对来自多种数据源的流数据进行处理,因此广泛被应用于物联网(IoAT)的数据处理。
通过上面的主流工具,我们基本上能解决99%种场景下的数据采集工作,数据采集完之后,就要面临一个不得不考虑的问题:采集的数据存在哪里?


